
Omniomics: The Bold Vision of Seeing the Cell in Its Full Complexity
Imagine a scenario where every molecule inside a single cell, including DNA, RNA, proteins, and more, is no longer a mystery, but part of a beautifully connected system we can fully observe. Not in isolation. Not in fragments. But as a complete, living map. This is the vision behind omniomics, an ambitious next step in biology where multi-layered molecular data come together to reveal the full complexity of life at the cellular level. As we stand at the cusp of this revolution, the question is no longer if we will get there, but rather how and when.
This article takes you on a journey through the evolution of omics, exploring not just the science, but also the innovations and obstacles that shape our path toward a future where omniomics becomes a reality.
What Is Omniomics and Why Does It Matter?
As envisioned by researchers Jongsu Lim and colleagues in their 2024 paper “Advances in Single-Cell Omics and Multiomics for High-Resolution Molecular Profiling,” omniomics represents an ambitious future direction in multiomics. It aims to “capture and characterize all molecules within a cell” by integrating genomic, transcriptomic, proteomic, epigenomic, metabolomic, and other molecular layers to define the complete cellular phenome, the full spectrum of a cell’s phenotypic expression.
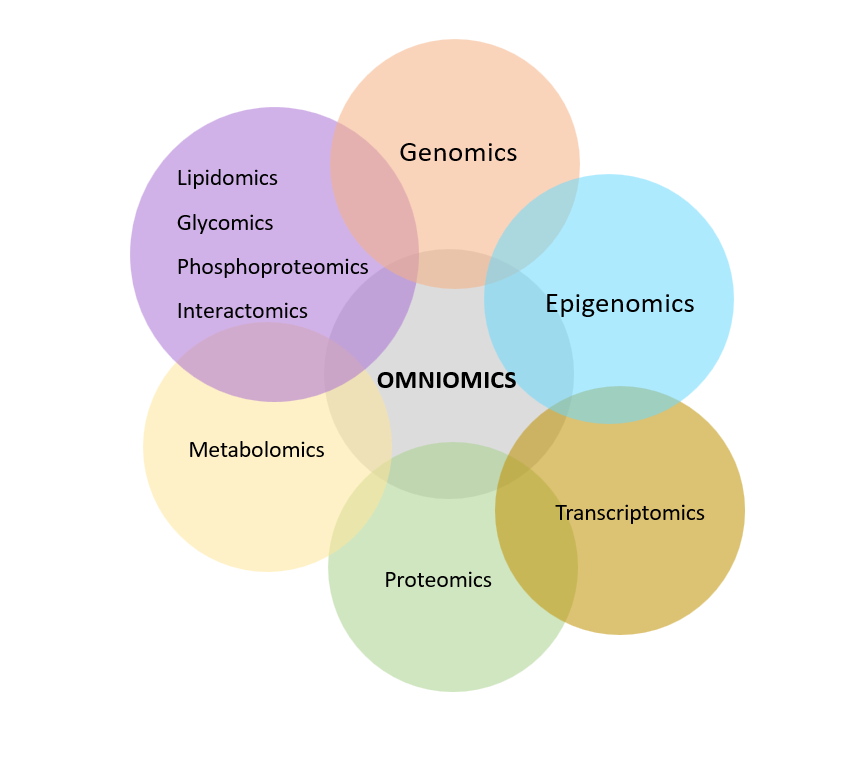
Figure: Multi-layered approach of omniomics
Note: Lipidomics, glycomics, phosphoproteomics, and interactomics are niche omics branches that would contribute to the overarching goal of achieving omniomics.
What happens if we crack this approach? The possibilities are astonishing, as it could help decode intricate biological interactions and disease mechanisms with far greater precision. In developmental biology, it might map the complete molecular dynamics of cell differentiation, revealing how various omics layers interact to drive developmental trajectories. It could also transform drug discovery by uncovering novel therapeutic targets and optimizing the drug design process. And in precision medicine, it could provide a robust understanding of cellular heterogeneity within tumors, enabling more personalized and time-sensitive treatment strategies.
How Did It All Start and How Far Have We Come?
To understand the road to omniomics, we must first rewind and trace the evolution of omics itself.
- For years, bulk mono-omics technologies dominated the field. From the 1970s through the early 2000s, researchers primarily used bulk approaches to study proteomics, transcriptomics, and early metabolomics. However, these methods provided averaged data across cell populations, often masking cellular heterogeneity and complexity. A major turning point came in 2009 with the development of the first single-cell RNA-sequencing (scRNA-seq) method, enabling the profiling of individual cells based on their distinct molecular characteristics. Gradually, single-cell mono-omics began to flourish. For the first time, we could truly hear what each cell had to say.
- Despite this progress, single-cell approaches have historically focused on one omics layer at a time, such as the transcriptome or proteome, a strategy known as single-cell mono-omics. The next leap forward began in the mid-2010s with the introduction of bulk multi-omics technologies. Integrating multiple omics layers such as genomics, transcriptomics, epigenomics, and metabolomics allowed researchers to unlock the intricate molecular interactions that govern cell behavior. Since 2019, the field of single-cell multi-omics has continued to grow rapidly, offering more detailed molecular profiles of individual cells.
- Now, the spotlight is shifting to spatial omics, a rapidly advancing field since the 2010s. It enables the analysis of biological molecules in their native locations within tissues, offering crucial insights into cellular interactions, microenvironments, and tissue organization. Why does this matter for omniomics? Because location drives function. Spatial omics adds the “where” to the “what,” complementing single-cell and multi-omics data and moving us closer to a systems-level view. It is yet another essential step toward the complete molecular map that omniomics promises.
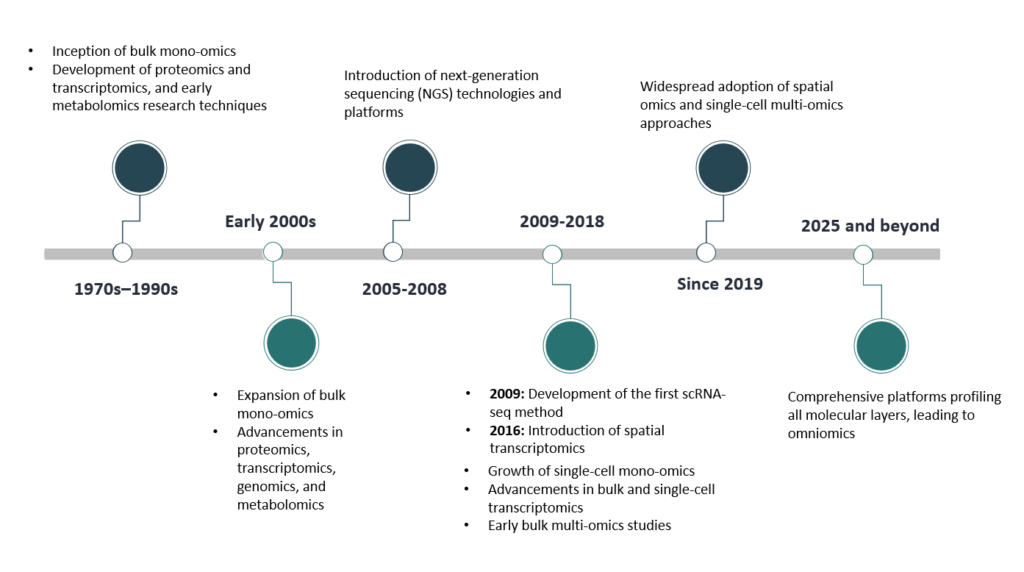
This journey, from bulk to single-cell, from single-layer to multi-layer demonstrates how the field is steadily advancing toward the ambitious goal: omniomics, where no molecular layer is left unexplored.
Which Technologies Are Leading the Way?
Omniomics aims to capture the full molecular complexity of individual cells by simultaneously profiling all omics layers. Achieving this requires more than just technical precision; it demands state-of-the-art molecular imaging technologies, seamless integration across diverse data types, and scalable analysis pipelines. Fortunately, a new wave of advanced technologies is now shaping the path forward, each unlocking a new layer of insight on the road to achieving omniomics.
(i) Technologies Enabling Multi-Layer Profiling of Individual Cells
Single-cell multi-omics studies have emerged as powerful tools for studying complex biological processes at the level of individual cells. These methods enable the simultaneous analysis of multiple omics layers—including genomics, transcriptomics, proteomics, and epigenomics—within the same cell. When these molecular dimensions are examined together, researchers can gain a more complete and nuanced understanding of cellular behavior, regulation, and interactions.
The figure below illustrates several variations of single-cell multi-omics approaches, each tailored to explore different combinations of molecular layers.
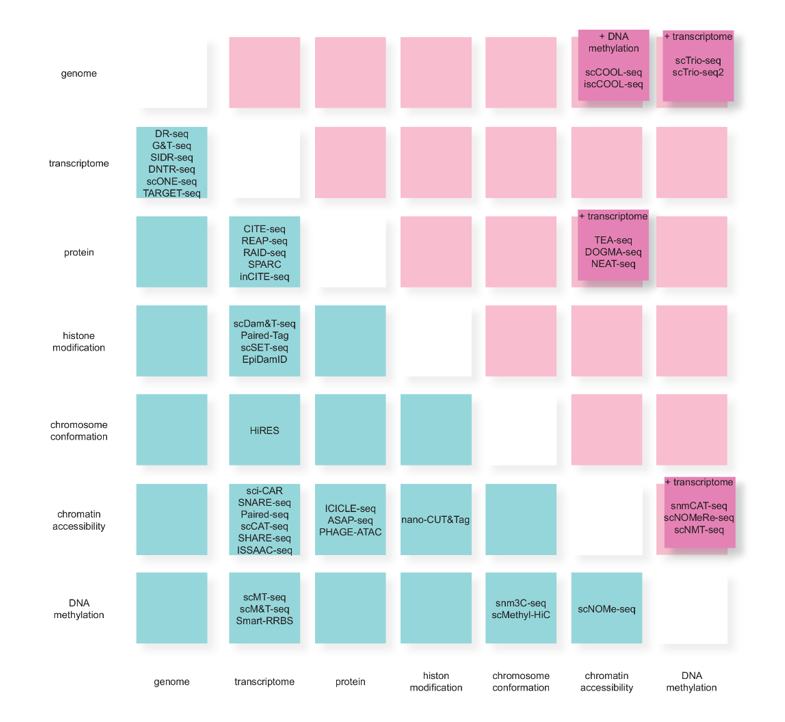
(Blue box: Dual omics technology; Magenta box: Technology that handles three or more omics simultaneously)
Adapted from: Lim J, et al. Exp Mol Med. 2024;56(3):515–526.
(ii) Long-Read Sequencing Technologies
A complete genomic profile is critical for understanding how DNA variations influence other molecular layers, making long-read sequencing a cornerstone for capturing the cellular phenome. Long-read sequencing technologies have emerged as promising solutions in this aspect. These technologies such as Oxford Nanopore Technologies and PacBio Single Molecule Real-Time (SMRT) sequencing produce reads spanning tens to hundreds of kilobases. These longer reads allow for improved characterization of genomic regions, including long-range interactions, structural variations, and multiple repeat regions. The integration of this technology into multiomics research holds great promise for overcoming the limitations associated with short-read sequencing.
(iii) Integration of AI and ML in Multi-Omics Research
The integration of AI and ML in multi-omics research addresses the critical challenges posed by the scale, complexity, and heterogeneity of omics datasets. These advanced computational approaches offer capabilities such as:
- Identifying patterns and correlations across multiple omics layers
- Uncovering functional and regulatory interactions among genes, proteins, and metabolites
- Predicting cellular states, disease progression, and therapeutic outcomes
- Utilizing deep learning models to map inter-omics relationships
- Effectively handling high-dimensional multi-omics datasets
Several recent innovations highlight the progress in this area, including:
- Genomic Language Models (gLMs)
- The Molecular Twin AI Platform
- SLIDE (Significant Latent Factor Interaction Discovery and Exploration)
- Advanced deep learning frameworks specifically tailored for multi-omics integration
(iv) Emerging GRN Inference Techniques
Gene regulatory networks (GRNs) describe how molecular regulators, such as transcription factors, control gene expression. They are essential for understanding how cells function, respond to environmental signals, and how genetic variants can lead to disease. With the advent of single-cell sequencing technologies, researchers can now analyze regulatory relationships at the resolution of individual cell types. Yet, the challenge of deciphering such complex mechanisms from limited, independent data points remains significant.
Some recent efforts have led to notable methodological advancements that are helping to overcome these limitations.
- LINGER: The Lifelong Neural Network for Gene Regulation (LINGER), is an innovative approach that integrates single-cell multi-omics data, specifically, gene expression (scRNA-seq) and chromatin accessibility (scATAC-seq) with large-scale external bulk datasets spanning diverse cellular contexts. Its core innovation lies in lifelong learning, a machine-learning mechanism that allows the model to retain prior knowledge gained from bulk data while continuously adapting to new single-cell inputs. This helps address longstanding challenges in the inference of GRN, including data sparsity and large parameter spaces that hinder complex model fitting. Compared to existing tools, LINGER demonstrates significantly improved accuracy in inferring GRNs by striking a balance between prior knowledge retention and adaptability to new data.
- GCN-based approach: A novel graph convolutional network-based approach guided by causal information has been developed to infer GRN. Unlike traditional methods, this approach uses transfer entropy to quantify and enhance neighbor aggregation, enabling the model to capture more accurate causal interactions. Additionally, it incorporates linear layers to support causal feature reconstruction, minimizing information loss during training. A Gaussian-kernel Autoencoder is employed to extract distinct features from gene expression data, improving both the computational efficiency of the GCN and the precision of causal inference. Together, this framework enables the construction of GRNs that are biologically meaningful, accurate, and interpretable.
(v) New Approaches to Studying Intercellular Communication
Cell–cell communication (CCC) encompasses multiple mechanisms, including ligand–receptor signaling, extracellular vesicle-mediated transfer, and direct physical contact, which are critical for regulating complex biological processes such as development, immune response, and disease progression. In the context of omniomics, understanding these interactions is critical, as it can:
- Provide functional context for interpreting molecular data, revealing how cells work together within tissues interact to form functional units
- Help identify rare cell types and transient cell states, which are essential for extensive molecular characterization
The widespread availability of single-cell data, especially of transcriptomics, has spurred the development of numerous computational tools designed to decipher cell–cell communication. (See a comprehensive list of bioinformatic tools for inferring CCC here: https://www.nature.com/articles/s41392-024-01888-z/tables/2).
What is Holding Us Back?
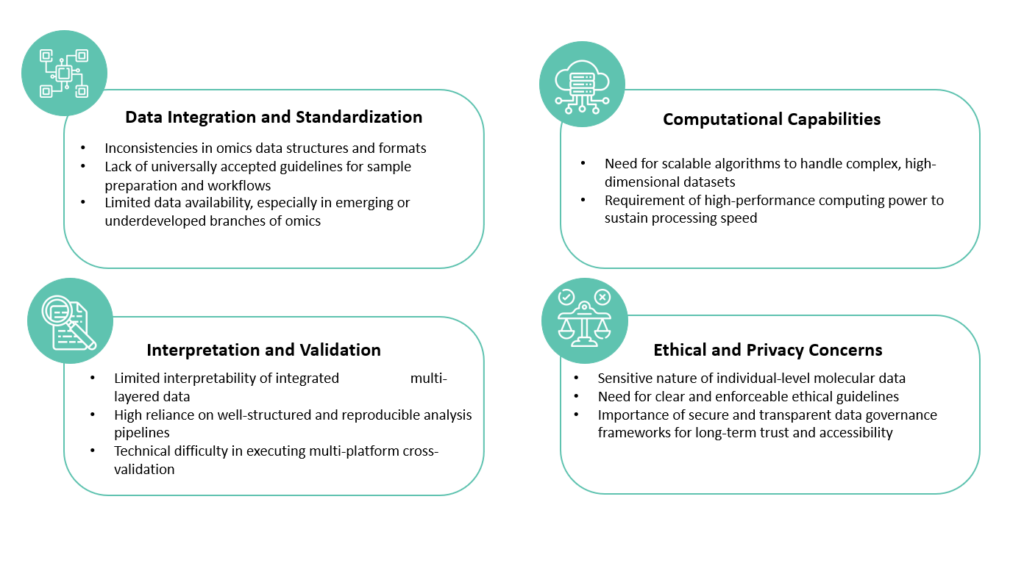
Let’s not sugarcoat it. Omniomics is a highly ambitious vision, and achieving it comes with substantial hurdles. The complexity of biological systems, combined with technical, computational, and ethical constraints, creates a challenging landscape. Yet, recognizing these barriers is key to developing viable solutions.
Here are some of the major roadblocks currently standing in the way of progress:
What Will Take Us the Rest of the Way?
Omniomics is a technological milestone that signifies a paradigm shift. It invites us to see the cell not as a static list of molecules, but as a dynamic, interwoven system. As Lim et al. emphasize, “significant advancements toward omniomics” are expected soon. We are closer than we think, but only if we dare to imagine it. Whether you are a researcher, technologist, or part of an emerging biotech force, your role matters. From global initiatives like the Human Cell Atlas to industry-driven roadmaps from companies like Illumina, the shift has begun. The call is clear: omniomics is ours to shape. Let’s be the ones to dream it, design it, and deliver it together.
References
- Lim J, Park C, Kim M, et al. Advances in single-cell omics and multiomics for high-resolution molecular profiling. Exp Mol Med. 2024;56(3):515–526.
- A focus on single-cell omics. Nat Rev Genet 24, 485 (2023).
- De Coster W, De Rijk P, De Roeck A, et al. Structural variants identified by Oxford Nanopore PromethION sequencing of the human genome. Genome Res. 2019;29(7):1178–1187.
- Wei L, Niraula D, Gates EDH, et al. Artificial intelligence (AI) and machine learning (ML) in precision oncology: a review on enhancing discoverability through multiomics integration. Br J Radiol. 2023;96(1150):20230211.
- Yuan Q, Duren Z. Inferring gene regulatory networks from single-cell multiome data using atlas-scale external data. Nat Biotechnol. 2025;43(2):247–257.
- Ji R, Geng Y, Quan X. Inferring gene regulatory networks with graph convolutional network based on causal feature reconstruction. Sci Rep. 2024;14(1):21342.
- Su J, Song Y, Zhu Z, et al. Cell-cell communication: New insights and clinical implications. Signal Transduct Target Ther. 2024;9(1):196.
- Flores JE, Claborne DM, Weller ZD, et al. Missing data in multi-omics integration: Recent advances through artificial intelligence. Front Artif Intell. 2023;6:1098308.
- Mohr AE, Ortega-Santos CP, Whisner CM, et al. Navigating Challenges and Opportunities in Multi-Omics Integration for Personalized Healthcare. Biomedicines. 2024;12(7):1496.
- Bonev B, Castelo-Branco G, Chen F, et al. Opportunities and challenges of single-cell and spatially resolved genomics methods for neuroscience discovery. Nat Neurosci. 2025;28(1):216.
- Lahnemann D, Koster J, Szczurek E, et al. Eleven grand challenges in single-cell data science. Genome Biol. 2020;21(1):31.
- Regev A, Teichmann SA, Lander ES, et al. The Human Cell Atlas. Elife. 2017;6:e27041.
- Illumina transforms multiomic research with new technologies to unlock deeper understanding of biology. Available at: https://investor.illumina.com/news/press-release-details/2025/Illumina-transforms-multiomic-research-with-new-technologies-to-unlock-deeper-understanding-of-biology/default.aspx.